Motivation
While working on my personal website to procrastinate other, more important things, I recalled Patrick Collison’s famous personal website, which I’d seen years earlier, and thought about his virtual bookshelf. I had been thinking about adding some kind of “what I’m learning” section to my site, and I thought I’d like to have something like his bookshelf, but more information-rich. For starters, I take pretty thorough notes on all of the technical content I read these days, so I thought that having a linkable notes section would be a cool way to convey progress-in-motion as well as to function as an eventual high-fidelity signal of understanding. Such notes ought to be useful to potential visitors to boot!
Then I had an idea, which began with a very simple insight. I’d been thinking recently about how interesting sqlite is: nothing but a single file and some software to treat it as a database. You want to delete the database? Delete the file. You want to clone the database? Copy the file. And so on and so on. No daemon. No user privileges. No pgdump. Anyone with the software can treat it as a database. There’s a lot of beauty in the simplicity.
But anyways, I’d noticed a few days ago, while I was working on my laptop, an Arch machine, that zathura, which I use as a pdf reader for its vi-style-movements, was logging something about sqlite whenever I opened a file:
info: Opening plain database via sqlite backend.
warning: sqlite database already exists.
Set your database backend to sqlite
On my primary work machine, I run Debian 12 right now, and I’d never seen this log message, but that’s not important just yet. So now I know that zathura uses sqlite under the hood, which I love: perfect storage model for downloadable open source software! In fact, as I realized, it makes zathura extensible beyond code. Without needing to run a fork of my own, nor even to learn an API (let alone to make one, from the project developers’ perspective), I could extend the functionality of the app by simply interacting with its database directly – something sqlite makes easy to do from something as simple as a bash script.
The idea was simple: use sqlite queries to the zathura database to fetch progress updates on my personal studies. Like a digital bookshelf with digital bookmarks.
I’d noticed that zathura always reopens my pdf files to the last opened page, so I knew the sqlite database would have my current page number somewhere, and it took moments to find it:
[lane@minifridge ~/.local/share/zathura]$ ls
bookmarks bookmarks.sqlite history input-history
[lane@minifridge ~/.local/share/zathura]$ sqlite3 bookmarks.sqlite
SQLite version 3.40.1 2022-12-28 14:03:47
Enter ".help" for usage hints.
sqlite> .tables
bookmarks fileinfo history jumplist
sqlite> .schema bookmarks
CREATE TABLE bookmarks (file TEXT,id TEXT,page INTEGER,hadj_ratio
FLOAT,vadj_ratio FLOAT,PRIMARY KEY(file, id));
sqlite> .schema fileinfo
CREATE TABLE fileinfo (file TEXT PRIMARY KEY,page INTEGER,offset
INTEGER,zoom FLOAT,rotation INTEGER,pages_per_row
INTEGER,first_page_column TEXT,position_x FLOAT,position_y
FLOAT,time TIMESTAMP,page_right_to_left INTEGER,sha256 BLOB);
sqlite> SELECT page, file FROM fileinfo LIMIT 1;
0|/home/lane/Lane-Russell.pdf
Lol jk, it was not that simple at all. I wish. In fact, I had not misremembered: my Debian machine did not log the same messages about sqlite, nor any for that matter, and there was no bookmarks.sqlite in my ~/.local/share/zathura/ (yet!). So it was pretty apparent at that point that the default Arch (pacman) and Debian (apt) packages for zathura were not the same thing. So step one was to uninstall the apt package and build zathura from source, which was surprisingly annoying, given that the dependencies are all named different things in apt. Thanksfully, good ole ChatGPT made short work of resolving translations like listed dependency librsvg-bin = librsv2-dev or error message missing dependency msgfmt = gettext.
Eventually, I had everything working, and the sqlite backend was enabled by default on the source build, so there was no further work.1
Gathering the Data
Next: a bash script to pull pdf info with pdfinfo and my current page number from zathura (via the sqlite database), and use it to compute progress for a list of books, which I’d simply keep in a file alongside my “bookshelf” (a.k.a. ~/books).
#!/bin/bash
# Filename: progress-zathura.sh
READING_LIST="$HOME/books/reading_list.txt"
ZATHURA_DB="$HOME/.local/share/zathura/bookmarks.sqlite"
# confirm pdfinfo is installed
if ! command -v pdfinfo &> /dev/null; then
echo "pdfinfo not found, please install poppler-utils."
exit 1
fi
# confirm sqlite3 is installed
if ! command -v sqlite3 &> /dev/null; then
echo "sqlite3 not found, please install sqlite3."
exit 1
fi
# get page count from pdfinfo
get_page_count() {
pdfinfo "$1" | grep 'Pages' | awk '{print $2}'
}
# get current page from zathura's database
get_current_page() {
sqlite3 "$ZATHURA_DB" \
"SELECT page FROM fileinfo WHERE file = '$1';"
}
while IFS= read -r file; do
# check if file exists
if [ ! -f "$file" ]; then
echo "File does not exist: $file"
continue
fi
total_pages=$(get_page_count "$file")
current_page=$(get_current_page "$file")
if [ -z "$current_page" ]; then
echo "No reading progress found for: $file"
continue
fi
# calculate progress
progress=$(bc <<< "scale=2; ($current_page+1)/$total_pages*100")
title=$(pdfinfo "$file" | \
grep 'Title' | \
cut -d':' -f2- | \
sed 's/^[[:space:]]*//')
author=$(pdfinfo "$file" | \
grep 'Author' | \
cut -d':' -f2- | \
sed 's/^[[:space:]]*//')
echo "Title: $title"
echo "Author: $author"
echo "File: $file"
echo "Progress: $progress%"
echo
done < "$READING_LIST"
(Note that all of the scripts will be on my github)
To make things easier to add to/remove from my reading list, I’d need to actually extend zathura, which is also easy and vi-like.
First, the scripts I’d need to call with my zathura key-bindings:
#!/bin/bash
# Filename: add-to-reading-list.sh
READING_LIST="$HOME/books/reading_list.txt"
# add to reading list
echo "$1" >> "$READING_LIST"
# send notification
notify-send "Reading List" \
"Added $(basename "$1") to reading list."
#!/bin/bash
# Filename: remove-from-reading-list.sh
READING_LIST="$HOME/books/reading_list.txt"
# temporary file for new reading list
TEMP_LIST="$(mktemp)"
# ensure temporary file is removed on script exit
trap 'rm -f "$TEMP_LIST"' EXIT
# remove filename from reading list w inverted grep
grep -vFx "$1" "$READING_LIST" > "$TEMP_LIST" && \
mv "$TEMP_LIST" "$READING_LIST"
# send notification
notify-send "Reading List" \
"Removed $(basename "$1") from your reading list."
(note that you’ll need libnotify-bin installed to display the notification with notify-send)
And then the actual key-bindings:
# Filename: zathurarc
# see https://man.archlinux.org/man/zathurarc.5
map <C-a> exec "/path/to/add-to-reading-list.sh $FILE /path/to/log/file.log 2>&1"
map <C-r> exec "/path/to/remove-from-reading-list.sh $FILE /path/to/log/file.log 2>&1"
# ...
(in actuality, my zathurarc is autogenerated from a template by wal as part of my color scheme, so I am actually changing the template)
So now, the next time I open up one of the books I’m reading in zathura, I can hit ctrl + a to add it to my reading list, and then at any time I can run progress-zathura.sh from the command line to get something like this:
[lane@minifridge ~]$ progress-zathura.sh
Title: Deterministic Operations Research
Author: David J. Rader & Rader Jr
Progress: 9.00% (73/743)
Title: Introduction to Linear Algebra, 5th Edition
Author: Gilbert Strang
Progress: 38.00% (223/585)
Scope Creep
2024-04-10T11:02:42-07:00
Okay, so I loved how this all came together, but then I realized that this would actually be a pretty useful tool for me, and I was a bit discontented by the fact that most of my non-technical reading is in Audible, because I prefer audiobooks.2 So, as an careless, throw-away hail mary, I googled “Audible api” and was totally dumbfounded when I saw it existed.
Of course I have to use it!
So I wrote a python script to log in, fetch my library, and record some data: add new books to my database, check unfinished, in-progress books for progress (comparing against previous records), and mark others as finished when necessary.
In the spirit of SQLite appreciation, I decided to use my own local SQLite database to track my Audible state with two tables: audible_books and audible_progress
CREATE TABLE IF NOT EXISTS audible_books (
asin TEXT PRIMARY KEY,
title TEXT,
subtitle TEXT,
author TEXT,
description_html TEXT,
runtime_minutes INTEGER,
is_finished BOOLEAN,
image_url TEXT,
public BOOLEAN DEFAULT FALSE,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
CREATE TABLE IF NOT EXISTS audible_progress (
id INTEGER PRIMARY KEY AUTOINCREMENT,
asin TEXT,
permyriad_complete INTEGER,
minutes_listened INTEGER,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
FOREIGN KEY(asin) REFERENCES audible_books(asin)
);
And then I simply fetch my library state:
with audible.Client(auth=auth) as client:
library = client.get(
"1.0/library",
num_results=1000,
response_groups="contributors, media, product_desc, product_details, listening_status, pdf_url",
sort_by="-PurchaseDate",
)
Because any new additions to my audible library will show up first, I only have to iterate until I find a book that’s already in my database when I check for new books (which is usually zero iterations). After that, I fetch all of the unfinished books from my local database:
cursor.execute('''
SELECT asin,title,author,runtime_minutes
FROM audible_books
WHERE is_finished = 0
''')
unfinished_books = cursor.fetchall()
Then fetch their current state from audible:
for book in unfinished_books:
with audible.Client(auth=auth) as client:
listening_status = client.get(
f"1.0/library/{book[0]}",
response_groups="listening_status",
)['item']['listening_status']
And filter out all the ones I haven’t started:
permyriad_complete = int(listening_status['percent_complete'] * 100)
# threshold to avoid e.g. 0.1% progress being recorded as "in progress"
threshold = 100
if permyriad_complete < threshold:
# haven't started listening yet, so skip
continue
(Permyriad?3)
Or mark any I finished since my last check as is_finished:
if listening_status['is_finished']:
cursor.execute('''
UPDATE audible_books
SET is_finished = 1
WHERE asin = ?
''', (book[0],))
conn.commit()
So that I can check it against its current local state (from the last checkmark):
cursor.execute('''
SELECT permyriad_complete FROM audible_progress
WHERE asin = ? ORDER BY created_at DESC
''', (book[0],))
result = cursor.fetchone()
And finally calculate the values necessary to insert a new progress record:
MYRIAD=10_000
# ...
last_permyriad_complete = 0 if not result else result[0]
permyriad_progress = permyriad_complete - last_permyriad_complete
if permyriad_progress > 0:
# either started a new book or made progress on an existing one
minutes_listened = round(permyriad_progress * book[3] / MYRIAD)
cursor.execute('''
INSERT INTO audible_progress (asin, permyriad_complete, minutes_listened)
VALUES (?, ?, ?)
''', (book[0], permyriad_complete, minutes_listened))
conn.commit()
The idea is that, rather than merely snapshotting my current progress, this method will allow me to compute statistics on my reading progress. I could render graphs and charts from this data effortlessly, and it is stored in a reasonably compact, efficient manner.
… But now my zathura scripts are, well, woefully mogged by the second-thought audible script. That had to be fixed, and the result is too much to simply paste below – it will be made available on my github, but here’s the gist: I moved from a .txt file to a SQLite database (in fact, the same one as for the python script, now with analogous tables, zathura_books and zathura_progress) and introduced the same logic regarding incremental progress records.
The only complication came from how new books are added – of course I had to modify the add-to-reading-list.sh and remove-from-reading-list.sh scripts (now mkbook.sh and rmbook.sh), but it wasn’t quite that simple. Spoiler: I plan to run the checkpointing scripts as a nightly cron job, so we can assume checkpoints are regular. When I add a new book to my audible library, I either (1) start reading it that day (incredibly rare), in which case the next checkpoint will default to assuming the current state is equal to my reading that day, and it is added to my database as a book with a corresponding progress record of that number of minutes, or (2) don’t, in which case no progress will be recorded, and the first checkpoint that detects progress will be correct in assuming it happened in the preceding 24-hour window.
For my zathura workflow, it is not so simple! I have a ton of books and papers that I’ve already begun, and I anticipate that I’ll have others I don’t add to tracking before I’ve read enough to decide to continue, but I don’t want to have weird datapoints where, for instance, it says I read 400 pages of a textbook in one day, because I added it after I’d read the first 400 pages. So, when I add a new book, I actually create an initial progress record of the current page I’m on when I add it. Of course, this drops some would-be data from before my recordings (no daily progress records), but my total reading will still be correct.
get_current_page() {
sqlite3 "$ZATHURA_DB" "SELECT page FROM fileinfo WHERE file = '$1';"
}
# add a new book to the database
insert_book() {
local title=$1
local author=$2
local page_count=$3
local file=$4
sqlite3 $READING_DB <<EOF
INSERT INTO zathura_books (title, author, page_count, file)
VALUES ("$title", "$author", $page_count, "$file");
SELECT last_insert_rowid();
EOF
}
# add a progress record for a book
insert_progress() {
local book_id=$1
local current_page=$2
local pages_read=$3
sqlite3 $READING_DB <<EOF
INSERT INTO zathura_progress (book_id, current_page, pages_read)
VALUES ($book_id, $current_page, $pages_read);
EOF
}
# ...
id=$(insert_book "$title" "$author" "$page_count" "$file")
current_page=$(get_current_page "$file")
insert_progress $id $current_page 0
Bringing the Feature to Life
Now, I need to actually start recording this data systematically, storing it, and posting it to my website
In other words: cron job, SQLite, JSON file.4
I already explained that I’m using a SQLite database,5 and I’ve already hinted that I’m collecting data with a cron job,6 but I haven’t explained what I’ll actually do with the data I collect.
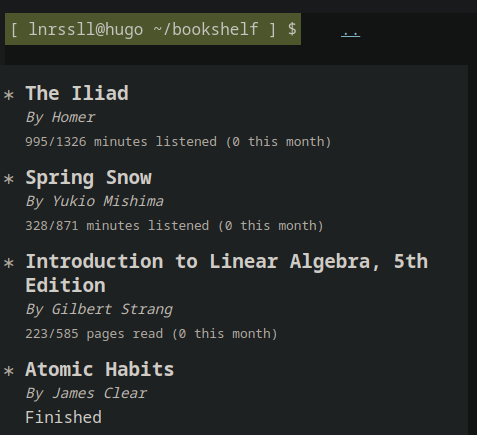
The first step will be to create another script that parses my data into only that necessary to render a minimal representation of whatever “view” I want on my website. So, e.g. I want a virtual bookshelf on my website that does the following:
- basic information about the book/document
- my current state (latest progress record) and maybe some basic 1-delta info, like “X minutes this week” or “Y pages this week”
Then I really only need something like this JSON:
[
{
"title": "Introduction to Linear Algebra, 5th Edition",
"author": "Gilbert Strang",
"is_finished": false,
"current_value": 223,
"total_value": 585,
"monthly_progress": 104,
"progress_units": "pages read"
},
{
"title": "The Iliad",
"author": "Homer",
"is_finished": false,
"current_value": 996,
"total_value": 1326,
"monthly_progress": 240,
"progress_units": "minutes listened"
},
...
{
"title": "The Master and Margarita",
"author": "Mikhail Bulgakov",
"is_finished": true,
"current_value": 1012,
"total_value": 1012,
"monthly_progress": 0,
"progress_units": "minutes listened"
}
]
This data doesn’t exist in the above form, so I’ll have to do some data wrangling. Step one is to design my query:
SELECT
title,
author,
is_finished,
current_value,
total_value,
monthly_progress,
progress_units
FROM (
SELECT
title,
author,
is_finished,
page_count AS total_value,
COALESCE(MAX(current_page),0) AS current_value,
COALESCE(SUM(pages_read),0) AS monthly_progress,
'pages read' AS progress_units
FROM zathura_books zb
LEFT JOIN zathura_progress zp ON zb.id = book_id
AND zp.created_at >= date('now', '-30 days')
WHERE public = true
GROUP BY title, author, is_finished, page_count
UNION ALL
SELECT
title,
author,
is_finished,
runtime_minutes AS total_value,
COALESCE(MAX(permyriad_complete*runtime_minutes/10000),0) AS current_value,
COALESCE(SUM(minutes_listened),0) AS monthly_progress,
'minutes listened' AS progress_units
FROM audible_books ab
LEFT JOIN audible_progress ap ON ab.asin = ap.asin
AND ap.created_at >= date('now', '-30 days')
WHERE public = true
GROUP BY title, author, is_finished, runtime_minutes
) AS combined
ORDER BY current_value DESC, monthly_progress DESC;
Obviously, that’s a lot, but to understand it is quite straightforward: begin with each subquery, name the columns identically, union them, then sort and select all.
Breaking down just the zathura subquery, as an example (the audible subquery will be perfectly analogous)
SELECT
title,
author,
is_finished,
page_count AS total_value,
COALESCE(MAX(current_page),0) AS current_value,
COALESCE(SUM(pages_read),0) AS monthly_progress,
'pages read' AS progress_units
FROM zathura_books zb
LEFT JOIN zathura_progress zp ON zb.id = book_id
AND zp.created_at >= date('now', '-30 days')
WHERE public = true
GROUP BY title, author, is_finished, page_count
We are collecting every progress record from the last month (30 days, technically)
SELECT *
FROM zathura_progress
WHERE created_at >= date('now', '-30 days');
3|9|223|0|2024-04-09 22:29:20
3|9|224|1|2024-04-09 22:30:20
But that is keyed off of the book_id, which doesn’t tell us much, so we need to join on the zathura_books table, which stores info like the title, etc. (we also need to now specific which created_at we are sorting by). We can also finally add a check for public = true now that the tables are joined. Note that the WHERE condition was turned into a LEFT JOIN condition, because otherwise all the NULL-valued zp.created_at values would be dropped, effectively turning the operation into a JOIN only.
SELECT *
FROM zathura_books zb
LEFT JOIN zathura_progress zp ON zb.id = book_id
AND zp.created_at >= date('now', '-30 days')
WHERE public = true
3|9|223|0|2024-04-09 22:29:20|9|Introduction to Linear Algebra, 5th Edition|Gilbert Strang|585|0|/home/lane/books/math/gilbert-strang-linear-algebra.pdf|2024-04-09 22:29:20|1
3|9|224|1|2024-04-09 22:30:20|9|Introduction to Linear Algebra, 5th Edition|Gilbert Strang|585|0|/home/lane/books/math/gilbert-strang-linear-algebra.pdf|2024-04-09 22:29:20|1
Great. Now we need to aggregate our data, by grouping like-rows (in our example, all of them) and selecting with aggregator functions like MAX() and SUM(), and add a literal string value for the data type (‘pages read’). Just like that, we’re back at the original query:
SELECT
title,
author,
is_finished,
MAX(current_page) AS current_value,
page_count AS total_value,
SUM(pages_read) AS monthly_progress,
'pages read' AS progress_units
FROM zathura_progress
JOIN zathura_books ON book_id = zathura_books.id
WHERE public = true
AND zathura_progress.created_at >= date('now', '-30 days')
GROUP BY title, author, is_finished, page_count
Introduction to Linear Algebra, 5th Edition|Gilbert Strang|0|224|585|1|pages read
COALESCE is just for fallback to a value (in this case, 0) in the case of NULL values, which do occur frequently: all books with no progress records will have null values where COALESCE is used after the LEFT JOIN operation.
To do the same for audible data, we need only note that the tables join on the asin (“Amazon Standard Identification Number”) and pages read terminology becomes minutes listened
The UNION ALL operation simply combines the output of our two queries, because we have to unify them before sorting, or we’ll get different book types out of order (note that I am not using any kind of conversion term for the “progress_units”, partially for simplicity and partially because, well, it just kinda works out I think that pages read correspond to minutes listened)
(Public?)7
Then, all I need to do is convert the output of my query into JSON:
# ...
cursor.execute(query)
query_results = cursor.fetchall()
columns = [column[0] for column in cursor.description]
result = [dict(zip(columns, row)) for row in query_results]
json_result = json.dumps(result, indent=4)
# ...
Maybe, eventually, I’ll want more info, like (as in Colisson’s Bookshelf) links to information about the book/document hosted on other sites, links to my own notes on technical material, or quick comments I deem necessary to add manually, like clarifying the specific version or translation of e.g. “The Iliad”. Thankfully, everything is constructed in a way to make this very easy to do! In most cases, more information will just mean adding a column (ALTER TABLE ... ADD COLUMN ... DEFAULT ...) and including it in the SELECT statement of our query, then adding it to whatever view renders this data in html.
Speaking of views, let’s talk about how I’m going to display this on my website! Since I’m using hugo, I’ll “jsonify” the output of my query and write it to the data directory of my hugo project. From there, hugo can pick up the rest of the work by rendering a collection of partials to display the data:
<!-- /layouts/partials/bookshelf.html -->
<h2>Books</h2>
<ul class="bookshelf">
{{ range $.Site.Data.bookshelf }}
{{ partial "book.html" . }}
{{ end }}
</ul>
<!-- /layouts/partials/book.html -->
<li class="book">
<p class="title">{{ .title }}</p>
<p class="subtitle">By {{ .author }}</p>
{{ if .is_finished }}
<p class="status">Finished</p>
{{ else }}
<p class="progress">
<span class="total-progress">
{{ .current_value }}/{{ .total_value }} {{ .progress_units }}
</span>
<span class="recent-progress">
({{ if .monthly_progress }}+{{ end }}{{ .monthly_progress}} this month)
</span>
</p>
{{ end }}
</li>
Now, with another nightly cron job,8 I’ll have fresh data written to the data dir of my website along with a site rebuild!
-
I later found, in the zathurarc (zathura config file) documentation that there’s a
databasekey that can be set to"sqlite", which appears not to be set by default, despite the"plain"option being deprecated. This is apparently because users of legacy versions ofzathurahave to run in"plain"mode to migrate their data into the new sqlite format before the"sqlite"setting can be safely assigned (without data loss). So I could have just changed the rc file setting, but (1) I built from source as a first step in case I was going to have to mess with the code and (2) it was a rewarding process nonetheless ↩︎ -
This is a whole thing, which I’m sure I’ll write about eventually, but here’s the tldr: I have bad double-vision, plus dyslexia, and my mind tends to wander when I read. Audiobooks fix all of this: I don’t have to look at anything, let alone printed words, and the audio stream is like a treadmill in that I will fall off if I stop walking (my mind wanders and I stop reading). As a bonus, I can do it while I wash dishes, drive, workout, etc.. So, say what you will about reading text, but I went from reading ~0 books on my own volition to >1 per month after discovering audiobooks. ↩︎
-
Audible’s
percent_completefield comes as a percentage, rounded to two decimal places. In a sense, this is just an integer up to 10,000 with a “dot” in it – functionally speaking, it would not be correct to call it a “float” or something, and treating it like one mathematically will lead to perhaps unexpected problems (e.g. open a python repl and compute0.1 + 0.2). Most will know that the Latin word for 100 is “centum”, and the prefix “cent-” is used generally to mean 100 in english. So, if a “percent”, or “per-100”, is an integer from 0 to 100, treated as a proportion of the maximum, then it feels sensible to call a number from 0 to 10,000, treated as a proportion of the maximum value, a “per-10,000”. There is no Latin word for 10,000, the same way there isn’t in English (“ten-thousand” in Latin is “decem millia”, and the translation is quite literal), but there is such a word in other languages: “man” in Japanese, “wàn” in (Mandarin) Chinese, and “myrias” in ancient Greek. “Myriad” is actually the english derivision of “myrias”, and so the choice of proununciation for “per-10,000” should be obvious: permyriad. This is almost equivalent to what, in finance, we’d call a “basis point”, but it is slightly different: percentage change in something, like a stock price, is not necessarily bounded in the same way a percentage is: you can change by negative percentages or by percentages greater than 100. So a basis point is more of a unit for comparison than completion and thus ill-fitting to our application. ↩︎ -
My website is a static hugo site served by Nginx, so rather than add a new backend API I’m just going to write data to a file and script a rebuild of the site (for now) ↩︎
-
It is often opined that software engineers have a tendency to over-engineer things in a “bringing a bazooka to a knife fight” kind of way. One common manifestation of this tendency is to use something like PlanetScale with MySQL and Prisma for a hobby project (it’s me; this example is me) that stores, let’s say, 3 users and a grocery list, with writes measured by the week. I am not worried about sqlite being unnecessary overhead, but I also don’t want to add unneeded complexity (and dependencies) if, for instance, a text file or csv will do. However, for this use case, my biggest concern is that I will start running the cron job and forget about this project for several years and have an enormous amount of data, so I’m going to use sqlite. It’s also probably just good practice. Further, I really like the idea of using this for a lot of pdfs – not just textbooks. I want to know what scientific papers, blogs, and articles I’ve read (or e.g. how far along I got), by saving them all as pdfs and reading them in
zathura. ↩︎ -
For anyone unfamiliar, a cron job is a scheduled command, which I’m using in this case to execute my scripts. So I just add a line to my
crontabby runningcrontab -eand then typing something like:0 0 * * * cd /path/to/script && venv/bin/python main.py -s, which means it will run on the zeroeth minute of the zeroeth hour of every ("*") day, month, and day of the week. ↩︎ -
You may notice there’s a “public” field included, which I haven’t previously mentioned. I chose to include a field to denote whether or not I’d want a particular book to be included on my website. I think the project is pretty, you know, transparent, but maybe I’m, like, embarassed about a book or, for example, it is none of your business lol Anyways, to facilitate this, I also have interactive scripts (in the repos) query the user for privacy preferences: each book is listed and you can y/n your way through the library to set public status. Changed your mind? Run it again. ↩︎
-
In actuality, there is only one cron job, which runs each script associated with this project in sequence, but it’s easier to just call each on a cron job. ↩︎
